GPU HPC Service
Top100 Supercomputing for AI
Training your large AI models on hundreds of Nvidia Tesla GPUs

High Performance Computing
Taiwan AI Cloud operates based on the strength of Taiwania 2, the supercomputer, which consists of 2,016 NVIDIA Tesla V100 32GB GPUs, delivering 9 PFLOPS of superior performance.
Taiwan AI Cloud High-Performance Computing provides a large number of GPUs with Spectrum Scale (GPFS) and an InfiniBand 100Gbps high-performance, low-latency internal interconnect network to assist you in the following ways:
- Meeting massively distributed computing needs.
- Accelerating computational iterations: HPC clustering environments can be leveraged for handling large computational workloads.
- Efficiently scheduling multiple GPUs across nodes to create a distributed high-performance parallel computing environment, achieving performance gains of up to 400% or more.
Starting at NTD $58/GPU/Hour

Train your own Llama-2 70B Model or BLOOM 176B Model using up to 2000 GPUs on-demand.
Fast, efficient, and low entry barrier.
LLM Ready-to-Go
The deployment threshold for LLM (Large Language Model) projects is exceptionally high, as enterprises are required to have expertise in building and fine-tuning an Artificial Intelligence High-Performance Computing (AIHPC) system, as well as conducting distributed training and large model inference.
With our GPU HPC Service, you will be able to swiftly reduce costs related to hardware equipment and human capital, while also mitigating development risks and shortening time to completion.
Successfully achieved linear acceleration results
Traditional cross-node distributed computing can experience performance degradation as the number of nodes increases. For example, if the computing power of one node is 100, according to linear theory, two nodes should have a combined computing power of 200. However, in practice, it might be reduced to 180 due to the decreased efficiency of inter-node communication and transmission.
In our cross-node distributed computing environment, the InfiniBand architecture effectively facilitates collaborative operation among nodes. This implementation allows the execution of the Formosa Foundation Model to achieve near-linear performance, providing nearly perfect high-performance validation. It helps users fully leverage computational power and ensure that every investment is utilized optimally.
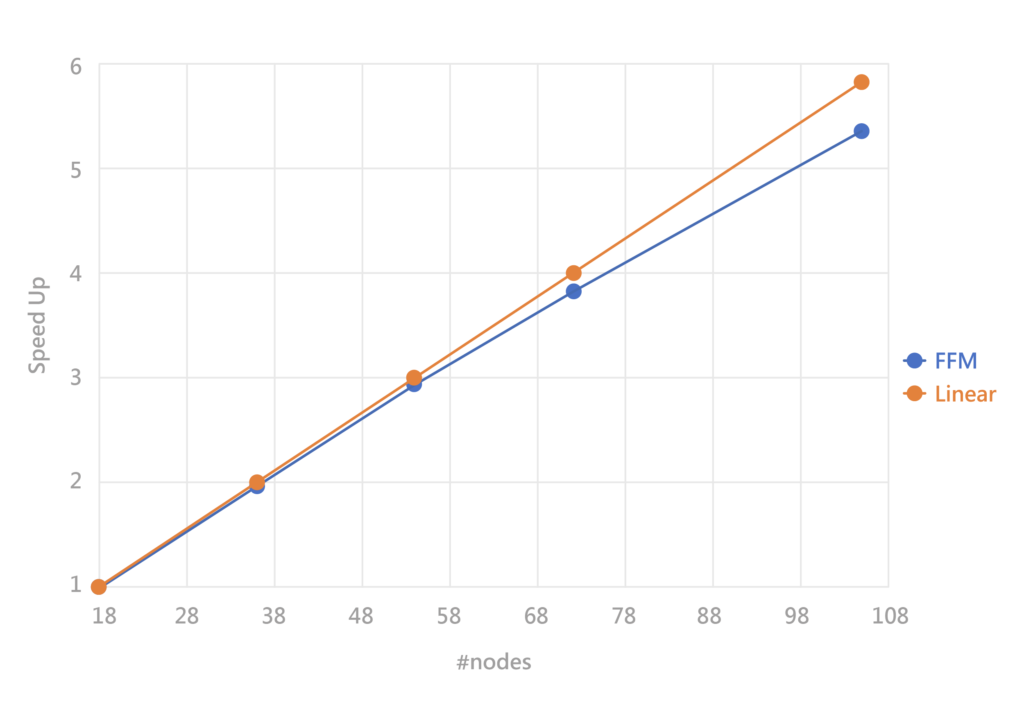
The FFM (Formosa Foundation Model) is trained by Taiwan AI Cloud and boasts an impressive scale of 176 billion parameters.
Biotechnology
Taiwan AI Cloud provides HIPAA and GDPR-compliant cloud infrastructure and services that accelerate system digital innovation, scientific technology development, pathology data analysis, and business agility with unparalleled confidentiality and security based on the needs of the healthcare system. Vast computing resources and a robust security environment may accelerate explorations in the medical field and service innovation, enhance sensitive data management, and strengthen environmental security compliance.
Computer Vision
Taiwan AI Cloud provides computer vision services that enable computers and systems to derive meaningful information from digital images, videos, and other visual inputs — and take actions or make recommendations based on that information. Enhance the benefits of multiple AI usage scenarios through GPU HPC Service. Scheduling multiple GPUs across nodes to achieve a distributed high performance parallel computing environment with performance up to 400% or more.
GPU-as-a-Service
Start training your models immediately with pre-configured software, shared storage, and networking for AI.
Powerful IaaS
We help you to deploy rapidly by supercomputer's architecture with Slurm/ Kubernetes, Ceph, Spectrum Scale (GPFS), CentOS, Singularity, etc.
Easy to use and familiar framework
Various Pre-configured software environments. AI Framework includes PyTorch, NeMo, RAPIDS and etc. Easy to use the tool to develop.
High Performance Computing
With InfiniBand 100G network. Large bandwidth network cascade nodes for high data transfer efficiency. GPU Direct and RDMA architecture for an ultimate acceleration of overall computing efficiency.
High-level Cloud Security
The high-level security infrastructure and multiple integrated services can fulfill users’ information security and compliance requirements to improve confidentiality, integrity, and availability.
Features
- Supporting a native HPC operating environment.
- Use of Slurm to schedule GPUs across nodes to achieve native high-performance distributed computing.
- Barenet machine operation, no virtualization, full performance.
- Supporting Singularity container environment.
- Allowing you to deploy large batches of computing jobs.
- Full integration of HFS, a fully-managed high performance distributed file system.
Runnable large models
- LLM requires precise model partitioning for distributed training
- Provide AIHPC cross-node supercomputer services
Run without burden
- Reasonable price / high CP value
- Capable of running multiple tests simultaneously to accelerate R&D process
- Option to choose larger-sized models
Run faster
- Cross-node GPU high-performance computing
- Infiniband 100G network
- IBM GPFS high-performance file system
- NVLink
Run better
- Professional service team
- Reduce migration cost
- Assist customers with LLM-related issues
FAQs

Please find the Pricing.
There are 2 ways to buy the GPU HPC Service.
1. Buy Redeem Coupon
Step.1
Click “Buy Now”. The more you buy, the more you save! Please refer to Credit card payment discounts for more details.
Step.2
After purchasing the coupon, please Sign in to the Member Center and redeem it. Please redeem your credit coupon within 1 month and spending all your credit within one year is recommended. The coupon is an anonymous redeem coupon so that you can use it yourself or give it as a gift to others.
2. Buy Credits
Step.1
Sign up as a member: It takes only 10 minutes to complete the project function from zero. (Please go directly to the next step if you have already registered.)
Step.2
Sign in Here; or click “Buy Now” on the Member Center page; to enter the Member Center and take an online payment. The more you buy, the more you save! Please refer to Credit card payment discounts for more details.
Step.3
Enter the user portal and click on the project to start AIHPC-as-a-Service and secure IaaS service immediately.
Yes, please find the Free Trial Program.
As a Taiwan AI Cloud, Taiwan Web Service Corporation (TWSC) is a subsidiary of ASUS providing a world-leading AI supercomputing cloud platform to help customers establish AI solutions. Using Taiwan’s AI cloud platform services, it launched a commercial high-performance computing AIHPC supercomputer for the service industry in Asia. Intending to create an AI digital economic ecosystem, it is helping the industry quickly obtain AI intelligent applications and cloud architecture solutions of high efficiency and low barriers. We have provided AIHPC cloud computing resources for market digital research and development, cooperating with partners to carry out diversified industrial solutions including AI on 5G, hybrid cloud, data information, and blockchain, and assisting industries in building, training, managing, and deploying AI intelligent applications more quickly and flexibly. The objectives are to accelerate the digital development of start-ups and enterprises with the results of ESG’s carbon reduction layout and to achieve the goal of end customers of digital transformation and business expansion.
Free Consultation Service
Contact our experts to learn more and get started with the best solution for you.