+ 國家實驗研究院國家高整網路與計算中心
* 台灣智慧雲端服務公司
內容摘要
宇宙模擬
仰望夜裡的星空,我們看到浩瀚無垠的宇宙外,也不禁會思索宇宙想述說給我們的所有故事還有在這個時空中可能存在的各種可能,正如 Star Trek 所說的 “Space: the final frontier.”。在機器學習與人工智慧的浪潮下,人類有了新的機制可以試著透過深度學習(Deep Learning, DL) 機制以暸解探索宇宙的物理與天文特性,讓收集來自宇宙的能量波、電磁波、動力波及暗能量(Dark Energy)等均能在類神經網路結構中萃取出其資訊特徵進而詮釋及預測各種天文現象。然而新型態 DL 機制在天文宇宙資料上是具挑戰性的工作。由於收集到的天文科學資料非常的多維度(資料中可能包括三維或四維度的多頻道資料)且龐大(資料量在 TB-PB 起跳),加上要能快速驗證各項科學假設及實驗結果,整個應用 DL 流程必需要能在多維度的實驗資料中很有效率運行,此對服務工程面更是一大挑戰。
為了能透過電腦模擬宇宙的運動,最單純的作法是透過 N-body simulation 來計算星體在不同引力影響下的運動過程。參考 Josephbakulikira 所提供的模擬框架 N-body-simulation-with-python–Gravity-solar-system[1] ,其中在 Body::Calculate() 中將重力影響下計算每個星體之間的引力(下方程式碼 L7)、加速(L10)及投射值(L6),
# code block copy from https://github.com/Josephbakulikira/N-body-simulation-with-python--Gravity-solar-system/blob/master/utils/body.py
def Calculate(self, bodies):
self.acceleration = vector.Vector2()
for body in bodies:
if body == self:
continue
r = vector.GetDistance2D(self.position, body.position)
g_force = (self.mass * body.mass)/ pow(r, 2)
acc = g_force / self.mass # acceleration a=f/m
diff = body.position - self.position
self.acceleration = self.acceleration + diff.setMagnitude(acc)
並將各星體的運動軌跡繪制出來(如下圖)。

在更進一步的模擬,可能需要加入更多星體、更多星體間的引力關係到多維空間之中。如下面影片中的宇宙 N-body 模擬 ,在 1萬個星體物件下 10萬光年距離裡,宇宙生成呈現的棒旋星系(Barred-Spiral galaxy)運動結果。
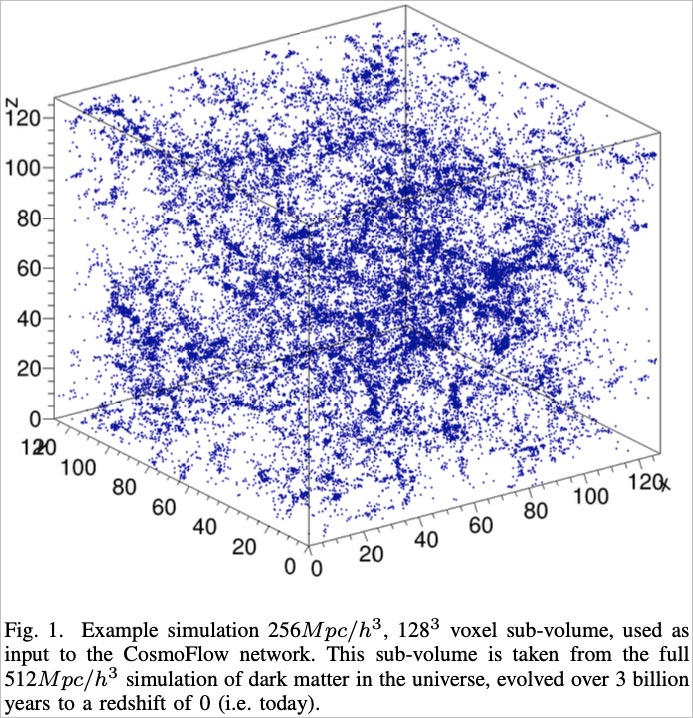
宇宙模擬是透過建立天體物理模型,
以模擬星體間可能的運動方式。
在 Mathuriya[2] 等人(2018) 的研究中,除了生成具暗物質的宇宙資料外,亦設計能在 HPC (High-Performance Computing, 超級電腦)中運行的機器學習演算法,希望能利用當代深度學習(Deep Learning)技術,以加速在大量資料中爬梳出宇宙分佈特徵。機器學習流程以模擬資料為輸入資料,並將模擬資料的參數(包括 σ8每小時8百萬秒差距, Ωm宇宙中物質的比例, N 時空共動切片的曲率)為預測結果,完整的深度學習模型概念圖如下:
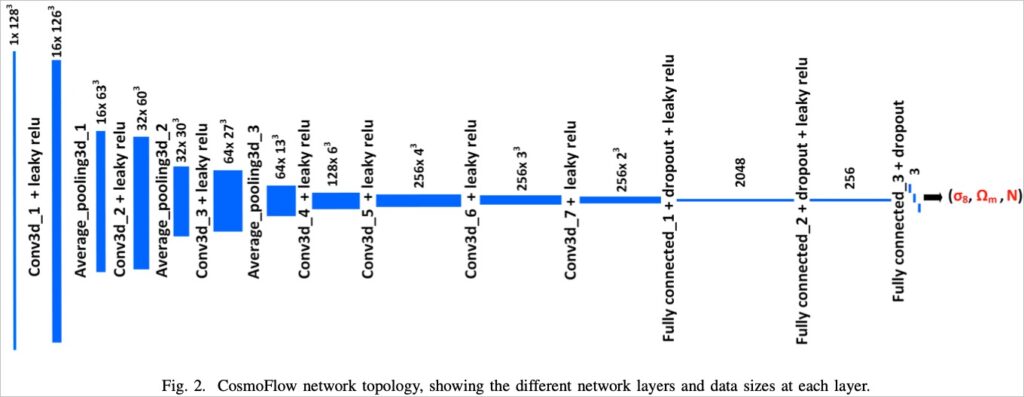
上圖深度模型架構為 7 層 CNN (Convolutional Neural Network, 卷積神經網絡) 及 3 層全連通網路(Fully connected layer) 與 Krizhevsky, Sutskever, 及 Hinton (2012)[3] 所提出 AlexNet 架構(下圖),為 5 層 CNN 及 3 層全連通網路,兩者極為相似,均是透過 CNN 將資料參數的區域特徵學習至特徵圖(feature map) 層後,並結合全連通網路以預測學習結果。

然而對應於宇宙模擬資料的機器學習問題來說,為了能有效率地進行大量資料學習,Mathuriya[2]等人(2018) 則更著重在如何完整利用 HPC 的平行計算資源以加速整理的學習效率,相關策略包括使用 Intel® 提供 MKL-DNN, NVIDIA 的 cuDNN® 與 NCCL 套件,以達成高效率實驗目的。為了能加速此類大規模宇宙機器學習的計算效率,由多國大學及超級電腦計算中心組成的 ML Commons®團體則以 Mathuriya[2] 等人(2018)的研究為基礎,並將能在將原來研究中提到的 20 天加速到 8.04 分鐘(加速約 3,600 倍),如此一來對於宇宙天體研究來說 HPC 的計算設施則是強而有力的實驗工具。
深度學習演算法能應用於宇宙模擬實驗中,
可透過 AI-HPC 計算設施得到 3,600 倍的實驗加速。
操作宇宙模擬資料的大規模深度學習
為了讓讀者可能實際操作宇宙模擬資料的機器學習,我們提供各位操作細節以臨摩 Mathuriya[2]等人(2018) 在 CosmoFlow 摸擬資料集上的深度學習研究。亦希望在此操作流程中,可概略暸解如何透過 HPC 達到 3600 倍人工智慧演算法加速效果。TWCC 服務中,包括台灣最大且為世界級的超級電腦 – 台灣杉二號 (Taiwania 2),本項操作則是在 Taiwania 2 的環境中進行。歡迎各界進來試用。
取得 CosmoFlow 資料集
CosmoFlow 摸擬資料集可以直接在 NERSC 的專案網站 (https://portal.nersc.gov/project/m3363/) 中透過 wget 指令取得,過程可參考 Guy Rutenbert[4] 的操作建議。然而在取得這麼大量的資料過程,往往會因為個人電腦所在的網路環境不穩定,造成資料下載不完整或缺失而需要續傳或重傳。在此建議使用您的 Google 帳號登入 globus 以取得研究資料。
實作:取得資料
{kind=link}

💁♂️ 若您是使用 TWCC 的 HPC 服務,在下載之前請先確認您的 HFS 高速檔案系統 已設定至合適大小,並透過查看 HFS 儲存空間使用容量 仍有剩餘空間,避免後面操作遇到問題。
在完成資料集下載後,就能開始進行小規模宇宙模擬資料集的深度學習訓練。
實驗流程
Step 1. 取得演算法程式碼
依循 ML Commons® 所提供的深度學習演算法,我們能開始在小資料量的宇宙模擬資料集上進行深度學習訓練。而然該原始碼提供版本 b21518c 中,我們發現有一些程式上的錯誤,建議可針對此版本進行修正,對應的 patch 檔如下:
請自行取得 b21518c 版本的程式碼。
diff --git a/train.py b/train.py
index 1a375fc..b67bed4 100644
--- a/train.py
+++ b/train.py
@@ -44,7 +44,7 @@ import tensorflow as tf
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '3'
tf.compat.v1.logging.set_verbosity(logging.ERROR)
import horovod.tensorflow.keras as hvd
-import wandb
+#import wandb
# MLPerf logging
try:
@@ -71,7 +71,7 @@ def parse_args():
"""Parse command line arguments"""
parser = argparse.ArgumentParser('train.py')
add_arg = parser.add_argument
- add_arg('config', nargs='?', default='configs/cosmo.yaml')
+ add_arg('--config', nargs='?', default='configs/cosmo.yaml')
add_arg('--output-dir', help='Override output directory')
add_arg('--run-tag', help='Unique run tag for logging')
@@ -228,7 +228,7 @@ def main():
logging.info('Configuration: %s', config)
# Random seeding
- tf.keras.utils.set_random_seed(args.seed)
+ #tf.keras.utils.set_random_seed(args.seed)
在上面的 patch 資料中主要修正幾點
- 移除掉
wandb函式庫。wandb為輔助模型權重及偏好參數的視覺化工具,在本次的工作中不對深度學習模型中的權重及偏好參數進行深入討論,從而建議移掉此函試。 config參數加入--維持參數的一致性。- 移掉隨機種子
set_random_seed設定。
Step 2. 在 HPC 環境中運行深度學習
為了能得透過 HPC 進行宇宙模擬資料集的深度學習實驗,我們需要先定義訓練工作檔,在此我們稱此檔為 job.sh。
詳細在 TWCC 運行 HPC 工作,可在 HPC 高速運算任務 文件中得到更多資訊。
#!/bin/bash
#BATCH -J MLPerf_HPC # 任務名稱
#SBATCH -o slurm-%j.out # 輸出日誌檔位置
#SBATCH --account=######## # TWCC Project id
#SBATCH --nodes=2 # 取用多少工作節點
#SBATCH --ntasks-per-node=8 # 取用每個工作節點運行多少 MPI
#SBATCH --cpus-per-task=4 # 取用每個工作多少 CPU
#SBATCH --gres=gpu:8 # 取用每個工作節點多少 GPU
#SBATCH --partition=gp1d
module purge
module load compiler/gnu/7.3.0 openmpi3
export NCCL_DEBUG=INFO
export PYTHONFAULTHANDLER=1
export TF_ENABLE_AUTO_MIXED_PRECISION=0
SIF=/work/TWCC_cntr/tensorflow_22.01-tf2-py3.sif
SINGULARITY="singularity run --nv $SIF"
cmd="python train.py --config configs/cosmo_small.yaml -d --rank-gpu $@"
mpirun $SINGULARITY $cmd
在上面的設定腳本中,我們定義了此工作相關內容,包括三個部份:
- L1~L9 為跨節點工作設定參數。在此範例設定為 2個工作節點,合計 16顆 GPU。
- L11~L21 為設定使用軟體模組與設定環境參數。其中 L19 為使用 TWCC 預先設定好的
tensorflow_22.01-tf2-py3SINGULARITY 容器工作環境。TWCC 中的 HPC 容器環境是與 NVIDIA 共同合作針對 Taiwania 2 特別設計的最佳化容器運行環境,用戶可自行取用。 - L22 為運行大規模運算工作。
在上述運行腳本正式運行之前,仍需要提供深度學習模型定義檔 configs/cosmo_small.yaml,其中設定為
# This YAML file describes the configuration for the MLPerf HPC v0.7 reference.
output_dir: results/cosmo-000
mlperf:
org: LBNL
division: closed
status: onprem
platform: SUBMISSION_PLATFORM_PLACEHOLDER
data:
name: cosmo
data_dir: /home/{TWCC_USRNAME}/data/cosmoflow/cosmoUniverse_2019_05_4parE_tf_small
n_train: 32
n_valid: 32
sample_shape: [128, 128, 128, 4]
batch_size: 4
n_epochs: 128
shard: True
apply_log: True
prefetch: 4
model:
name: cosmoflow
input_shape: [128, 128, 128, 4]
target_size: 4
conv_size: 32
fc1_size: 128
fc2_size: 64
hidden_activation: LeakyReLU
pooling_type: MaxPool3D
dropout: 0.5
optimizer:
name: SGD
momentum: 0.9
lr_schedule:
# Standard linear LR scaling configuration, tested up to batch size 1024
base_lr: 0.001
scaling: linear
base_batch_size: 64
# Alternate sqrt LR scaling which has worked well for batch size 512-1024.
#base_lr: 0.0025
#scaling: sqrt
#base_batch_size: 32
n_warmup_epochs: 4
# You may want to adjust these decay epochs depending on your batch size.
# E.g. if training batch size 64 you may want to decay at 16 and 32 epochs.
decay_schedule:
32: 0.25
64: 0.125
train:
loss: mse
metrics: ['mean_absolute_error']
# Uncomment to stop at target quality
#target_mae: 0.124
上述深度學習模型定義檔 configs/cosmo_small.yaml中可調控的參數非常多,包括:
- L3 輸出位置
- L11~L21 資料集來源及相關參數。在此需要設定
data_dir至您所下載宇宙模擬資料集位置,方可順利運行。 - L23~L32 為模型設定檔。
- L34~L36 為最佳化演算法與其參數。
- L38~L55 Learning Rate 超參數設定區。
- L57~L59 定義 Loss 函數及停止條件 (若需要)
在完成設定之後,即可透過指令將 job.sh 提交至 Taiwania 2 中進行運算,指令為
sbatch job.sh
大規模實驗加速結果比較
透過上節中的說明,相信各位都能使用 Taiwania 2 超級電腦進行宇宙模擬資料的大規模深度學習,並且能在不同的參數及深度學習框架下進行最佳化(時間最短)的實驗。在此,我們亦分享幾個實驗工作的比較結果,包括使用不同版本深度學習(Tensorflow, MxNet)進行不同 GPU 數量與不同資料集版本(CosmoFlow 資料集 v0.7 and v1.0) 間的跨節點訓練比較,如下圖:
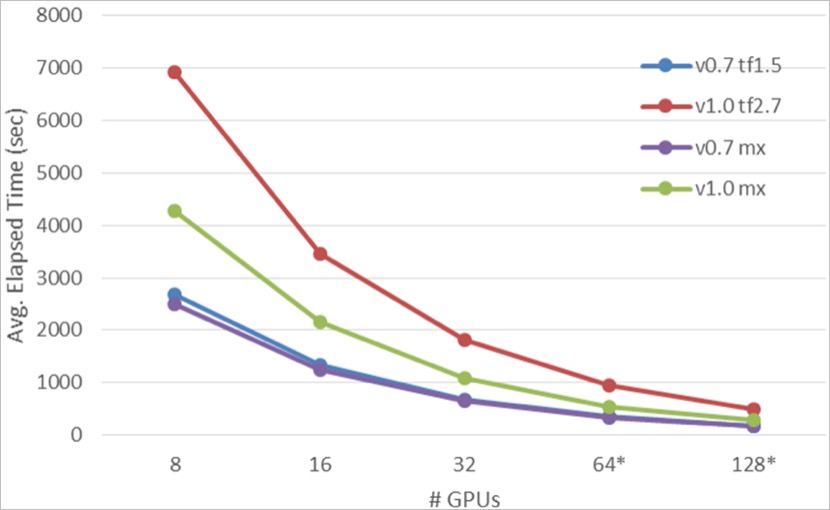
在上圖中,Y 軸為運行時間(Time to Mean average error 0.124)、X 軸為跨節點 GPU 數量,曲線中,平均運行時間較低的較有效率。從實驗數據可發現 MxNet (綠色、紫色)均比 Tensorflow (藍色、紅色)在不同版本的 CosmoFlow 資料集中較有效率。這部份我們推斷是因為 MxNet 的資料集,在前處理部分已經經過解壓縮,而在 Tensorflow 計算工作中為運行時才進行解壓縮。更進一步討論跨節點運算加速效果來說,分析如下表:

在宇宙模擬資料的大規模深度學習實驗數據中可知,每多一個計算節點(Taiwania 2 單一計算節點為 8 顆 V100 GPU) 約可提高計算效率 2倍,從能將計算時間成本大符縮短約 14.7 倍,不僅提高實驗假設取得結果的效率,更可讓太空研究產出更有成果。
此外由於 Taiwania 2 為 ready-to-use 且提供大量 GPU 計算資源供國人使用的 HPC 環境,在 on-demand 計算成本計算下,整體計算成本更可有效控管。依上述實驗大規模深度學習實驗數據中 Tensorflow 學習 CosmoFlow 資料集 v0.7 的計算數據來分析,如下:

從上表可知為了能加快實驗結果取得,我們將跨節點的計算規模從原本的 8 GPU (1台計算節點)拉高到 128 GPU (16台計算節點)中進行計算,而整體計算成本從原來的 511 NTD 僅提高到 551 NTD,但計算效率確有 14.7 倍的加速。在不修改任何演算法計算邏輯及運算環境的前提下,人工智慧演算法能從 Taiwania 2 計算設施裡直接加快實驗效率,並有效的控管實驗成本。
結語
本篇內容我們說明可如何透過 N-body 模擬 進行宇宙天體計算,除了提出數個天體模型外,亦介紹如何在天體模型中加入更多天文物理假設的方式。而當代計算機科學學者 Mathuriya[2] 等人(2018) 提出使用大規模深度學習方式進行宇宙天體模擬資料的機器學習架構,並透過 HPC 環境以加速實驗取得各項假說驗證資料。在Mathuriya[2] 等人(2018) 的研究中,參考 Krizhevsky 等人(2012)[3] 所提出 AlexNet 架構所設計的演算法模型,能讓深度學習演算法針對具有暗物質的模擬天體資料進行學習。而整體的實驗過程亦透過ML Commons®團體將整個計算時間成本從原本的 20 天加速到 8.04 分鐘(加速約 3600 倍)。最後我們亦說明在中華民國政府出資所建的超級電腦 Taiwania 2 中如何進行 Mathuriya[2] 等人(2018) 的研究,除了比較不同深度學習框架的計算效率外,亦說明在Taiwania 2 使用大規模深度學習計算能在接進零成本(不修改程式碼、不修改計算框架)的前提下,直接取得高速計算的效益。
希望對天文研究有興趣的朋友,亦能到 TWCC 的 Taiwania 2 進行不同有趣的天體實驗!
引用文獻
GitHub Project Josephbakulikira/N-body-simulation-with-python–Gravity-solar-system
Mathuriya, A., Bard, D., Meadows, L., et. al., “CosmoFlow: Using Deep Learning to Learn the Universe at Scale,” SC18, November 11-16, 2018, Dallas, Texas, USA. https://arxiv.org/abs/1808.04728
Krizhevsky, A., Sutskever, I., & Hinton, G. E. (2012). Imagenet classification with deep convolutional neural networks. Advances in neural information processing systems, 25.
Guy Rutenberg, “Make Offline Mirror of a Site using
wget”, https://www.guyrutenberg.com/2014/05/02/make-offline-mirror-of-a-site-using-wget/