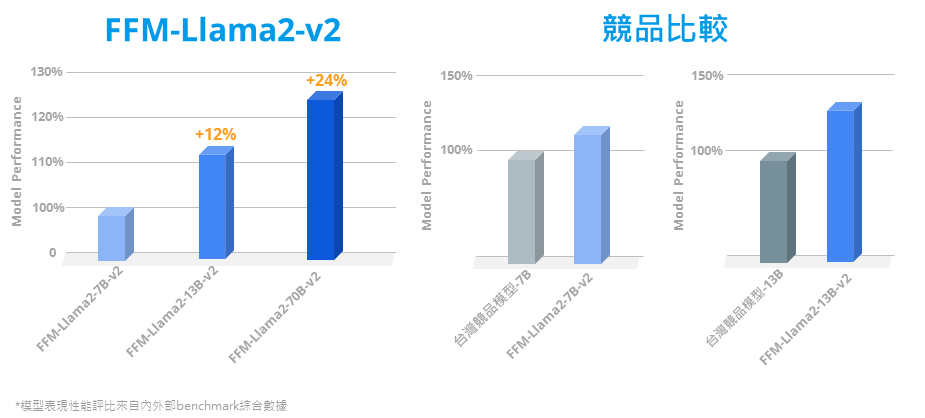
FFM-Llama2-v2 全球第一個繁體中文強化版的 FFM-Llama 2 (70B / 13B / 7B) 全系列模型,採用最新世代原生 Meta Llama 2 大型語言模型為基礎,運用 AIHPC 超級電腦算力、優化的高效平行運算環境、大語言模型切割技術和大量繁體中文語料進行優化訓練。v2新增繁中擴充詞表,提升繁中表現及推論效率。 FFM-Llama2-v2 ★ 全球首推繁中強化 Llama 2 大語言模型 ★★ 提供 FFM 大語言模型 70B / 13B / 7B 選項 ★ ★ 用戶可自訂系統角色提示詞,回應資訊更精準 ★★ 持續更新 FFM-Llama2-v2,新增擴充詞表,大幅提升繁中表現 ★★ FFM-Llama2-v2 降低繁中 Token 量 50%,模型推論效率加倍 ★ 申請試用 適用情境 大幅提升繁體中文能力,兼具原生 Meta Llama 2 優異的回應方式和能力 70B : 優異的結構化資料、表格、Markdown 理解與推理能力,資料表關聯與 SQL、JSON 能力,及 13B、7B 的各類適用情境 13B : 適合 Markdown 意圖分析 + JSON 格式輸出,及 7B 的各類適用情境 7B : 可用於行銷標語與內容生成、邀請函及郵件撰寫、中英翻譯、文章摘要、去識別化、聊天機器人問答 參數調整 Standard 全量參數微調 (Full parameter fine-tuning),使用特定任務資料集對預訓練模型的所有參數進行微調,需要大量的 GPU 運算與儲存資源。 PEFT 參數高效微調(Parameter-Efficient Fine-Tuning),固定大部分預訓練參數,僅微調少量額外的模型參數,降低了運算和儲存成本,同時趨近與全量參數微調的效果 (可適用的方法為LoRA)。LoRA : (Low-Rank Adaptation of Large Language Models),固定原本預訓練完成的模型參數權重,額外新增網絡層模組通路,透過高維度轉低維度的分解矩陣模組,僅對網絡層模組的參數進行更新,來模擬Full parameter fine-tuning的過程,大幅減少了所需訓練的參數量,降低了運算和儲存資源,以較少的參數量來實現大模型的間接訓練,且趨近於模型全面微調之效果。 免費諮詢服務 聯絡台智雲專家,了解並開始使用適合您的解決方案。 聯絡我們