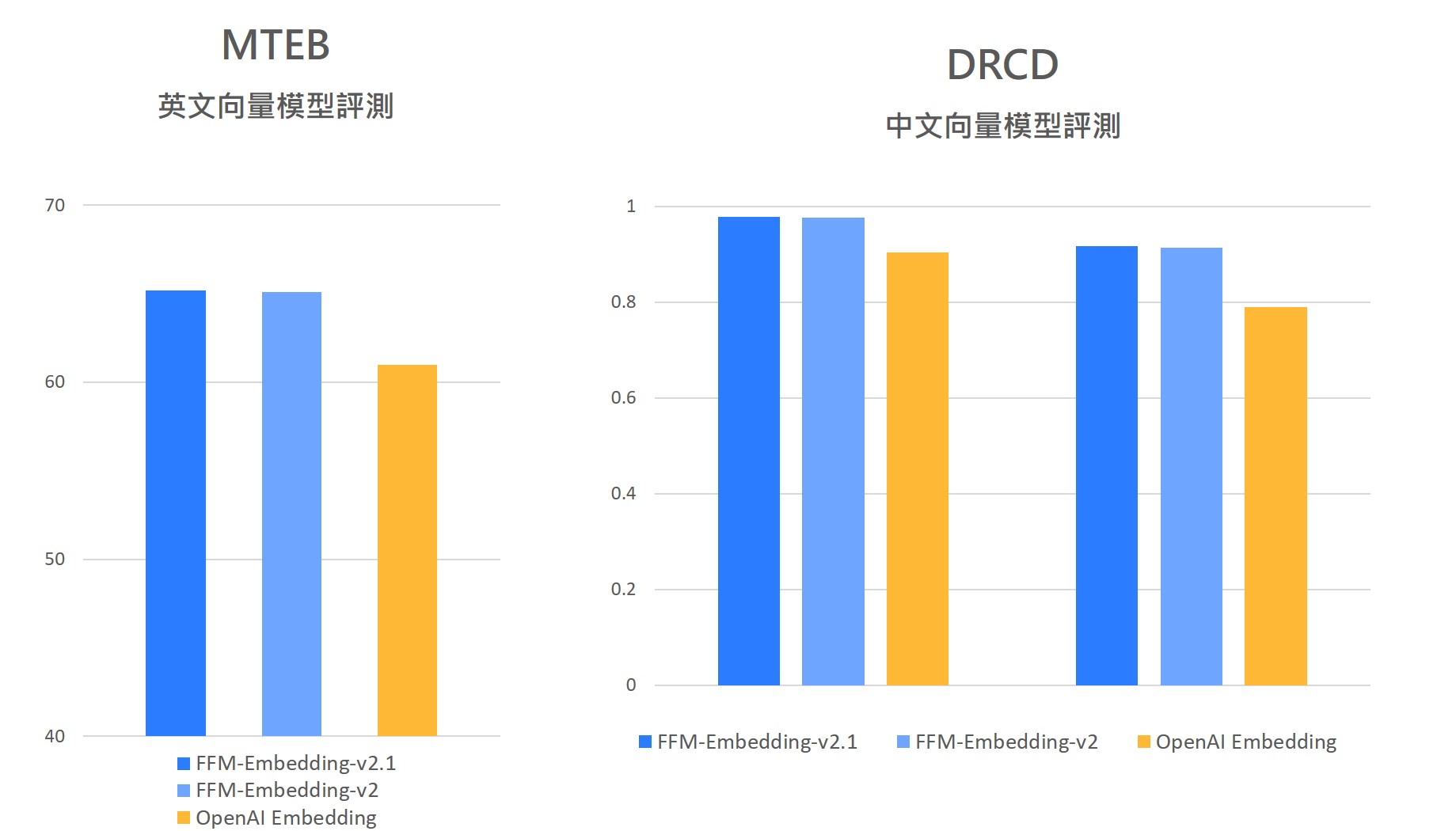
FFM-Embedding-v2 FFM-Embedding 為增強語意搜尋的向量嵌入模型,支援繁中及 8 種多國語言,v2 全面升級文本長度及向量維度,使資訊檢索更快速、語意更精確;v2.1 強化法律文本,加強識別法律術語和語境。 FFM-Embedding-v2 ★ 文本向量化工具,將複雜的文本資料轉換為向量 ★★ 用於資訊檢索、RAG(擷取增強生成)之向量建置及搜尋 ★★ 專注繁中向量,並支援 8 國語言(英/德/法/義/葡/印/西/泰)★★ 8K 文本長度大升級,提升檢索效率,快速處理大量資訊 ★★ 自訂義向量維度,最高至 2048,靈活調整,語意搜尋更精準 ★★ OpenAI 兼容,使用 OpenAI 之 Embedding API 可快速切換模型 ★★ 全新 v2.1 強化法律文本,加強識別繁中法律術語及語境 ★ 申請試用 評測超越 OpenAI 最優秀繁中向量模型 適用情境 完成複雜自然語言任務 透過 Embeddings 技術可以捕捉這些語言之間的含義,適用文字分類、問答系統、語意檢索、異常檢測、重新排序。 繁中及多國語言適用 FFM-Embedding-v2 專注於繁中向量,同時支援其他 8 種語言,使繁中及多國語言間的向量建置及搜尋更精準。 RAG(擷取增強生成) 向量模型對於 RAG 應用至關重要,Embedding-v2 支援 8K 文本長度及 2048 向量維度,使建置向量和檢索資訊更快速、更精確! 法律文件處理 自動化法律文件處理,例如合約審查、摘要、問答等,節省人力成本並提高效率,降低企業面臨的法律風險。 免費諮詢服務 聯絡台智雲專家,了解並開始使用適合您的解決方案。 聯絡我們